Pfizer/BioNTech C4591001 Trial - The 301 Mysteriously Missing Subject IDs Are Cause for Concern
111 missing in Argentina alone -- subject #12312982 shows us why it's unlikely to be "just a mistake"

Introduction
The software that assigned subject ID numbers for the Pfizer/BioNTech clinical trial generates ID numbers sequentially, which are assigned to volunteers when they are screened for inclusion in the study. We found 301 “gaps” in the subject ID numbers (missing numbers where there should be one), and in more than a few cases multiple sequential ID numbers in a row are missing.
Below, we start our in-depth investigation of this anomaly by reviewing how the software supervising the trial was functioning when a new subject was enrolled (“Enrollment” was the step prior to screening, where the subject was registered by the trial site, after the screening appointment had been coordinated through Pfizer’s subcontractor, ICON1).
Then we highlight why understanding this trivial detail matters as far as establishing a most concerning issue: the data of numerous subjects enrolled in the trial appears to be missing and may have been deleted.
We went in depth in verifying if the error we highlight was technically feasible and whether it could have an innocent explanation.
We must thank Christine Cotton2, a bio-statistician and among the first to denounce the trial, for the considerable time she dedicated to reviewing these concerns with us and helping us to ensure the data presented below is accurate.
Registration of a subject
ICON “pre-screened” potential trial subjects before they ever showed up at a physical trial site3, entering basic data such as age, race, weight & height, etc. Later in the trial, volunteers could also be recruited at the trial sites.
When a subject was registered, the ICON software (“Firecrest”, an interface synchronized by a central database powered by Oracle4 ) assigned that subject a unique and, importantly, incremental subject identifier ("subject id" - scalar "SUBJID" in the .XPT files):
- The first 4 digits designated the trial site identifier and were always the same for all the subjects of that same site. (In some cases subjects moved between trial sites during the study, so the full unique subject ID provided information on ‘current’ and ‘original’ site.)
- The last 4 digits designated the registration order, starting at 1001. The next subject registered at a given trial site was then numbered 1002, then 1003, etc.
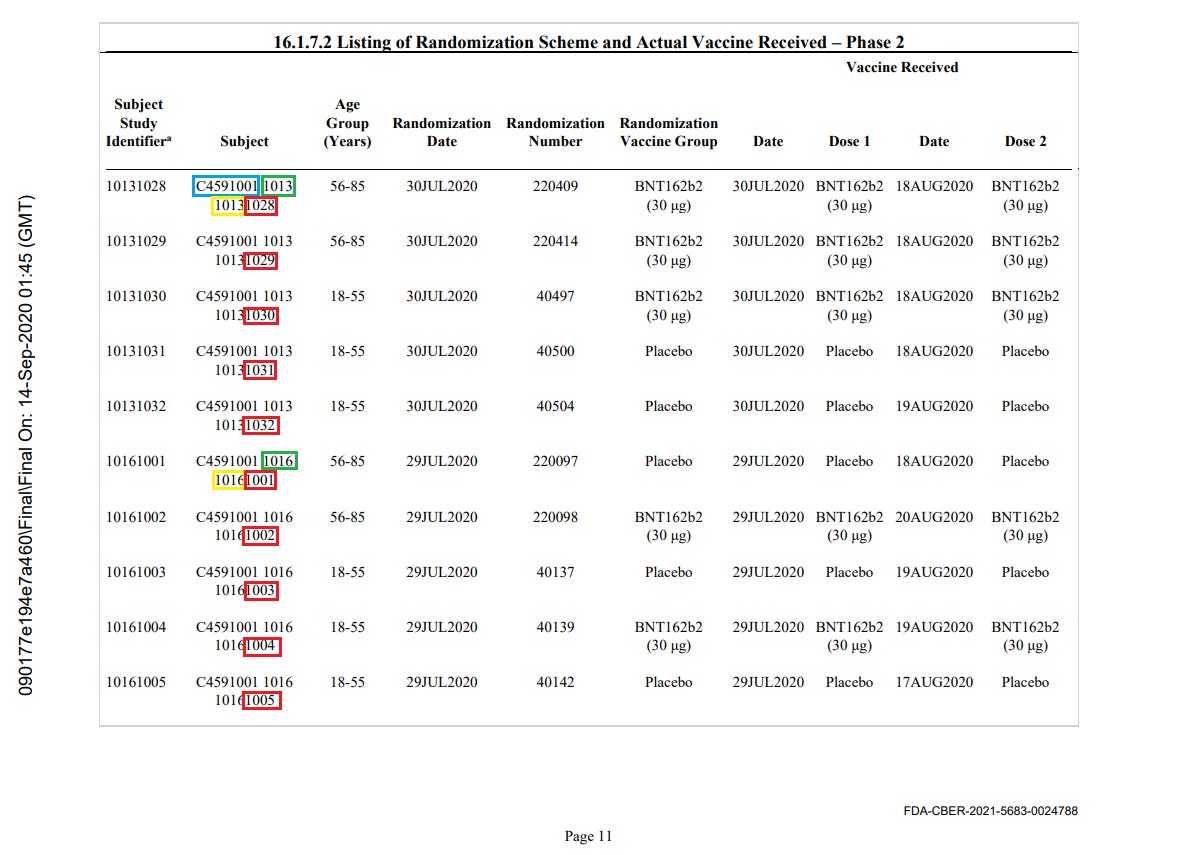
Circled in blue is the "study identifier" (always C4591001), circled in green is the current site identifier (here, 1016). Circled in yellow is the original registration site. Circled in red is the incremental subject identifier for this given site.

You can verify this phenomenon in this “one page extract” of a randomization export submitted to the FDA5.
Human errors could have occurred here & there (for example the investigator somehow initiating a new subject twice on a single person being screened).
Such exceptional errors could then be rectified, either by direct request to the “data manager” (ICON), or directly by a Principal Investigator on site, who would likely have had sufficient “data administration privileges” delegated to him by the data manager.
A more common way to deal with such issues would have been, on site, to define the subject as “Screen Failure” — though there are other reasons subjects failed the screening. The subject-level .xpt data files released in the Pfizer data dump include 1295 subjects marked as “screen failures.” These were people who eventually failed the screening for one reason or another, even though most had presumably been pre-screened by ICON.
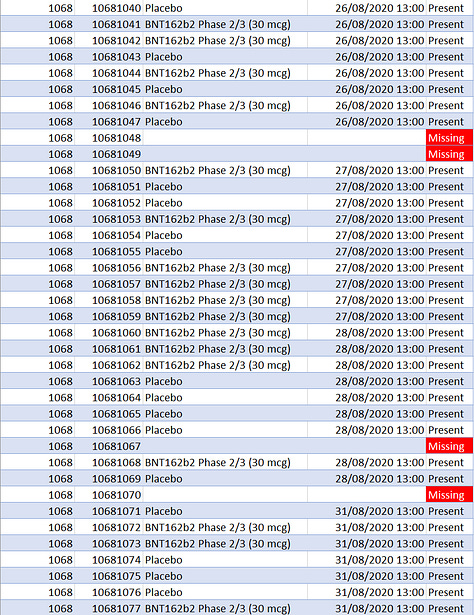
Subjects Disappeared
When we look at all the subjects registered for the Pfizer/BioNTech trial for all 3 phases ages 12 and up, we would then expect that the subject ID numbers would be sequential within each site. So for every site, the ID numbers should start at 1001 and continue sequentially (1002, 1003, 1004… etc). There should not be any gaps. But there are! There are 301 missing subject IDs, assuming that each site started recruiting at 1001 until the last subject ID registered at the site.
So naturally, we have to ask, why are these subject ID’s missing? Was this somehow a result of human or computer error, or is it an indication that these subjects and their data were deleted from the study for some reason? A few isolated missing ID numbers missing might be chalked up to human or computer error, but there is no reason we can think of why this would occur as they do ‘by mistake,’ though in theory it is possible and if anyone has an innocent explanation we’d love to hear it.
But there are certain aspects of these missing numbers that make us suspect intentional deletion. To begin with, if this was just due to error we would expect the subject numbering to skip one subject at a time here and there. And that does happen in many cases, but in some others the numbers “skip” in larger increments.
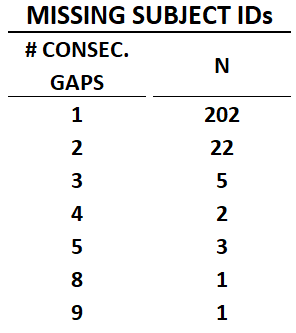
To be more precise, there are 202 single skips in the data, 22 times where two IDs in a row were skipped, five times where 3 were skipped, twice where 4 were skipped, three times where 5 were skipped, and once each where 8 and 9 consecutive ID numbers are missing.
To make sense of this pattern of skipped subject ID’s we need to believe that either:
- 1. A very poorly behaving computer decided to suddenly skip several numbers here & there to do the count on its own.
- 2. Or some very poorly behaving human being deleted data.
We believe that evidence and logic point towards the second hypothesis, but we are open to alternative explanations.
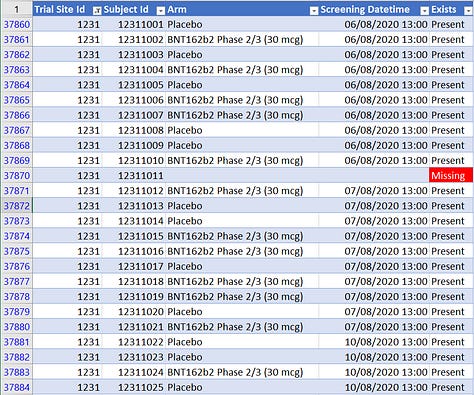
These rather abnormal offsets are illustrated in the screenshots below. The most anomalous ones are at infamous site 1231 with its (principal investigator’s self-proclaimed) “perfect data”.
How perfect? There are 111 missing subject ID’s at site 1231 (including 11 at pseudo-site 4444). Site 1231 had 5,896 subjects, which is 12.4% of the trial subjects, but it had 36.9% of all skipped subject IDs. Another way to look at it is that, if we add the missing IDs to the total number of subjects, Argentina is missing 1.8% of subject IDs compared to 0.45% of the remaining sites. In other words, the rate of missing subjects in Argentina is 4 times the rate at all other sites combined. (Obviously this difference is highly statistically significant.)
Said site’s PI - Fernando Polack - ended up as the lead author of the NEJM's "study of the century" - the public face of this gigantic fraud - thanks to his exceptional degree of corruption medical competence.
Augusto Roux6, a participant of this trial injured and gaslit by Fernando Polack, made himself too visible to be "just suppressed" and had the poor taste to survive his injuries. He has provided us with important insights on the way things were (mis-)managed at the Argentina site.7
Why is Augusto Roux’s story terribly important here?
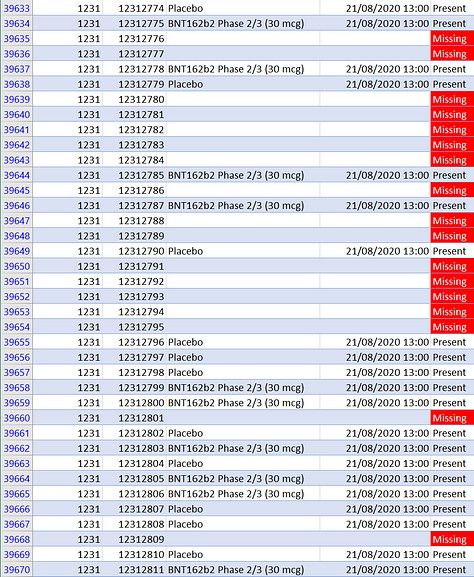
Well, as can be seen in the middle screenshot above, 17 subjects “disappeared” on a single day, August 21, 2020. That is by far the largest number of missing subject IDs at any site on any day. It is also the same day Augusto Roux was screened.
Since almost all subjects at the Argentina site were administered their first dose on the same day they were screened (if they passed screening), any subjects administered the first dose on that day would have been scheduled to receive their second dose three weeks later, the same date that Augusto received his, which caused him significant harm — possibly due to a bad batch.
Augusto Roux survived and was not erased from the study. Were there others, less fortunate, who were completely erased from the trial records? Or erased to cover up some problem? It’s possible. And it would not be far fetched to think that something could have gone wrong that affected 17 subjects on the same day, even 9 in a row. There was another major anomaly that occurred at the Argentina site just two days later, on August 23rd: 52 subjects on that day were given larger doses due to a preparation error and were subsequently unblinded a week later on August 31st. In the protocol deviation dataset,8 the reason given is “Dosing/administration error, subject did not receive correct dose of vaccine.” In other records there are other reasons given, but they are all product-related. We know from the trial records that 31 of them did not get the second dose, and of the 23 who did, four of them had significant adverse events recorded in the follow-up period after the second dose. So we know that there was a problem at this site that caused 52 consecutive subjects to be unblinded, which is a major screw-up and very anomalous. We also know that Augusto Roux's side effects were strangely re-defined (that is, covered up)9. In light of all this, it's reasonably to be suspicious when we see this huge anomaly of so many missing subjects on the same day that Augusto received his first dose.
The full table of 48 392 subjects (48 091 subject ids who remained, and the 301 subjects “simply deleted”), can be accessed (sorted by site & subject ID) on the following Google Spreadsheet (along with their randomization dates & treatment arm, when available)10.
Note there could very well be more subjects who have “been disappeared” (if for example a site’s last subject is 1198 but 1199 and 1200 were deleted, we would have no way to know it at this stage).
How Could Subjects Be Erased?
We can think of 3 ways in which these subjects could have been erased:
- 1. Directly in the database supervising the trial
Someone with database credentials (server, port, login, password) could have gained access, with or without ICON’s consent. Having such access would have allowed modification of any data of the trial (tests results, subjects data modification or erasing, etc.) directly to the database.
- 2. Upon the snapshot exports
In a similar fashion but leaving the “raw source data unaltered,” the .XPT data file exports or “snapshots” could have been altered, in order to fit a “predetermined result.” This would be easier to detect with an audit of the “core database” than method 1, but no such audit has ever been performed to our knowledge.
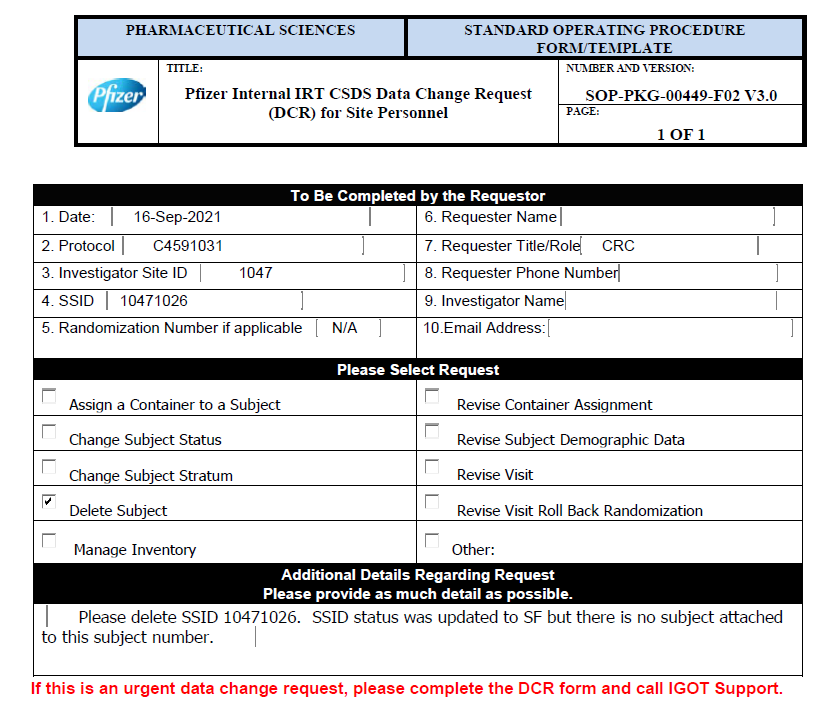
- 3. Via a request from the trial site to study sponsor
Below is a screenshot of a (redacted) request to Pfizer to delete a subject ID number originating from a trial site, which was provided to us by Pfizer whistleblower Brook Jackson. This is from the booster study, C4591031. As far as we know this request was granted. The reason given is: “SSID status was updated to SF [Screen Failure] but there is no subject attached to this subject number.” It’s unclear how this could have come about. It’s also possible this was an excuse used to delete a subject with problematic data. We don’t know. We also don’t know if the SSID would have been re-used by being assigned to another subject. But this is an example of the kind of error that might be expected to produce a handful of isolated, evenly distributed deletions.
- 4. Via the management software
The Principal Investigator on site could have been delegated “elevated privileges” allowing him or her to delete symptoms, or entire sets of subject data. If such privileges had been granted by ICON to Pfizer employees or site PIs, the only places where we could find evidence of the modifications would be the database logs & the audit trail accessible via the managing software. This constitutes, in our opinion, the most likely hypothesis, especially in light of the large number of deletions in Argentina.
Trial Sites where Subjects Disappeared
Most of the skipped subject ID’s are peppered here & there individually, and only 10 trial sites have more than 4:
- 9 subjects at site 1005 with 442 total subjects, Rochester Clinical Research, Inc. (Rochester, New York, USA), led investigator Matthew Davis.
- 5 subjects at site 1039 with 334 total subjects, Arc Clinical Research at Wilson Parke (Austin, Texas, USA), led by Gretchen Crook
- 5 subjects at site 1090 with 561 total subjects, M3 Wake Research, Inc (Raleigh, North Carolina, USA), led by Lisa Cohen
- 6 subjects at site 1109 with 557 total subjects, DeLand Clinical Research Unit (DeLand, Florida, USA), led by Bruce Rankin
- 6 subjects at site 1142 with 390 total subjects, University of Texas Medical Branch (Galveston, Texas, USA), led by Richard Rupp
- 5 subjects at site 1146 with 395 total subjects, Amici Clinical Research (Rajitan, New York, USA)
- 8 subjects at site 1147 with 340 total subjects, Ochsner Clinic Foundation (New Orleans, Louisiana, USA), led by Julia Garcia-Diaz
- 5 subjects at site 1166 with 107 total subjects, Rapid Medical Research, Inc. (Cleveland, Ohio, USA), led by Mary Beth Manning
- 5 subjects at site 1170 with 496 total subjects, North Texas Infectious Deseases Consultants, P.A. (Dallas, Texas, USA), led by Mezgebe Berhe
- 111 subjects (100 subjects at site 1231 with 4585 total subjects & 11 at site 4444 with 1,311 total subjects), Hospital Militar Central (Caba, Argentina), led by Fernando Polack
Such anomalies should happen extremely rarely if at all. And, if the problem was due to error, we would expect a fairly even or distribution across sites. But here we see 55% of deletions at 10 sites where only about 20% of all trial subjects were enrolled. And as we saw earlier, 37% of all deleted subjects were at a single site (Argentina) that enrolled only 12% of the trial subjects. The likelihood of such disproportionate deletions happening by chance is extremely low, far less than 1 in a million.
The code used to generate this first analysis is accessible on GitHub.
But Wait, There’s More!
A PDF document obtained via FOI (ASK-99541) to the European Medicines Agency (EMA), labeled "c4591001-interim-mth6-investigators.pdf", and created by Pfizer from an extract dated March 29, 2021, offers another very interesting insight on the recruitment & randomization by site11. A sample page is featured below.
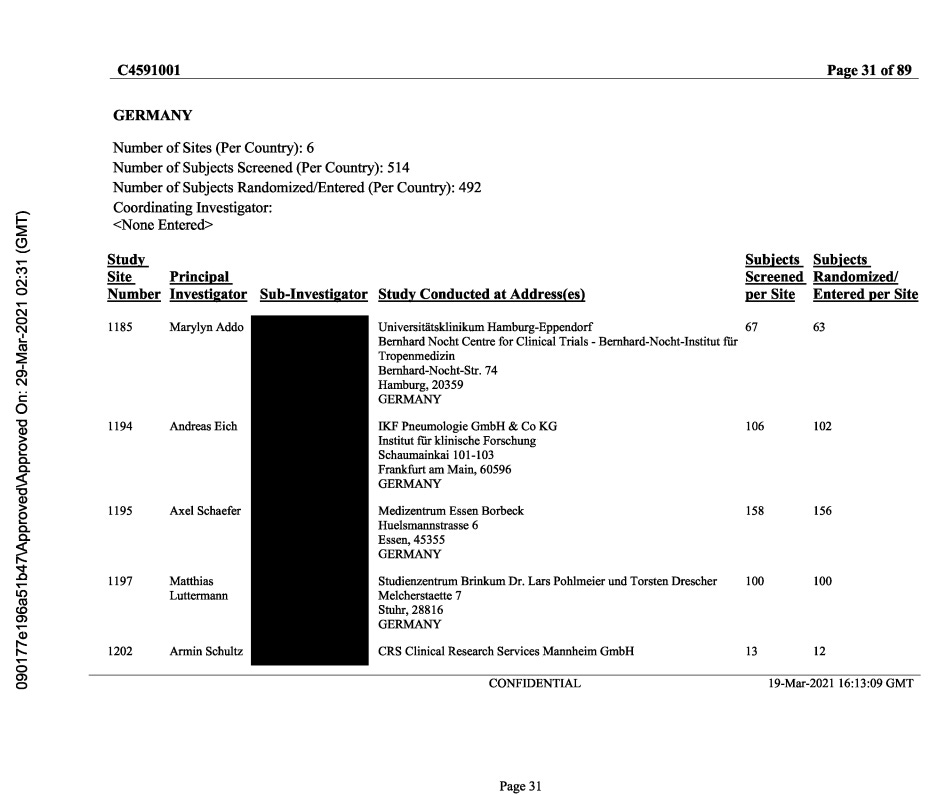
We compared the subjects screened & randomized, by sites, according to the ADSL file (Subject level data12) versus these “expected values”. The results are accessible in the following Google Spreadsheet13.
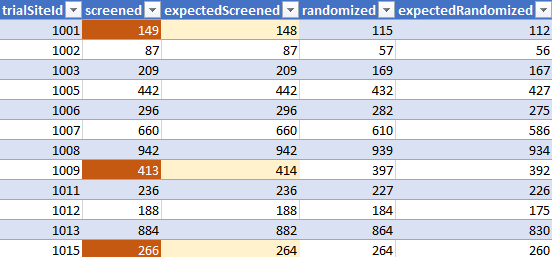
As illustrated in the brief sample above (focused on screening offsets), there are often discrepancies between the totals by sites, according to this data, and the totals reflected by the current ADSL file.
The total of subjects is very close (48 092 documented in this .PDF vs 48 091 in the ADSL file. But no matter if we test by original site of the subject (offset of 61) or if we test by current site (offset of 49), important differences are observed across sites between the expected and observed screening values (by absolute offsets).
Randomization offsets are even more important, but secondary to the current “subjects disappeared issue” - and they will be explored in more detail in a future post.
This constitutes further evidence - from the sponsors own extracts - that the number of subjects have been manipulated.
The code used to generate this last analysis is accessible on GitHub.
These various elements lead us to the conclusion that it’s urgent that the audit trails - containing the documentation of the export operations used to create these files - are released and that legal measures are taken to secure and investigate the database server’s data. We sent the FDA an inquiry asking for an explanation of these anomalies and received notification that they would look into it, but we haven’t heard anything yet. We will update if we do.
💬 Join the conversation
Want to like, comment, or share this article?
Head over to our Substack page to engage with the community.
Likes, comments, and shares are synchronized here every 5 minutes.
